Complete Guide To Pandas Dataframe Column Names
What are "Pandas Dataframe Column Names"?
Pandas Dataframe column names are the labels assigned to each column in a Pandas DataFrame, a tabular data structure in the Pandas library for Python. These names serve as identifiers for the data contained within each column, allowing for easy access and manipulation of the data.
The importance of Pandas Dataframe column names lies in their ability to provide context and meaning to the data. They help users understand the nature of the data in each column, facilitating data exploration, analysis, and visualization. Well-defined column names enhance the readability and usability of DataFrames, making it easier to work with and interpret data.
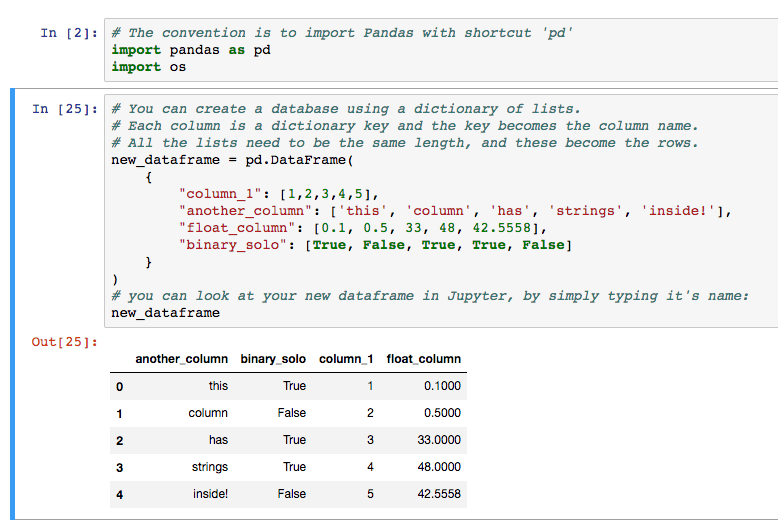
When creating a DataFrame, column names can be specified during initialization or added later using methods like `rename()` and `add()`. Choosing informative and descriptive column names is crucial for effective data management and communication.
Pandas Dataframe Column Names
Pandas Dataframe column names play a vital role in data manipulation and analysis. Here are 5 key aspects to consider:
- Identification: Column names serve as unique identifiers for each column, allowing for easy data access and manipulation.
- Context: They provide context and meaning to the data, helping users understand its nature and purpose.
- Readability: Well-defined column names enhance the readability and usability of DataFrames, making it easier to work with and interpret data.
- Standardization: Consistent and standardized column names facilitate data integration and sharing across different systems and teams.
- Metadata: Column names can be used as metadata to store additional information about the data, such as units of measurement or data source.
These aspects highlight the importance of choosing informative and descriptive column names when working with Pandas DataFrames. Well-named columns not only improve the usability and interpretability of data but also enhance collaboration and communication among data analysts and stakeholders.
Identification: Column names serve as unique identifiers for each column, allowing for easy data access and manipulation.
In the context of Pandas DataFrames, column names play a crucial role in identifying and accessing specific columns of data. Each column name serves as a unique label, enabling users to interact with and manipulate the data in a targeted manner.
- Data Retrieval
Column names allow for efficient data retrieval. By specifying a column name, users can directly access the corresponding data values without the need to iterate through the entire DataFrame.
- Column Operations
Column names facilitate various column-level operations, such as adding, removing, renaming, or modifying specific columns. This enables flexible data transformation and restructuring.
- Data Filtering
Column names are instrumental in data filtering operations. By using column names as criteria, users can select specific rows based on the values in a particular column.
- Data Aggregation
Column names provide a basis for data aggregation functions, allowing users to perform operations like summing, averaging, or counting values across specific columns.
Overall, the unique identification provided by column names is essential for effective data manipulation and analysis in Pandas DataFrames.
Context: They provide context and meaning to the data, helping users understand its nature and purpose.
In the realm of data analysis, context is king. Pandas Dataframe column names play a pivotal role in providing context and meaning to the data, enabling users to decipher its nature and purpose.
- Data Interpretation
Well-chosen column names act as signposts, guiding users in understanding the underlying meaning and significance of the data. They provide a frame of reference, helping users interpret the data accurately and draw meaningful conclusions.
- Data Exploration
Column names serve as a roadmap for data exploration. They allow users to quickly identify relevant columns and delve deeper into specific aspects of the data, facilitating a more efficient and targeted exploration process.
- Data Presentation
When presenting data to stakeholders, informative column names become even more crucial. They ensure that the data is self-explanatory and easily comprehensible, fostering effective communication and decision-making.
- Data Sharing
In collaborative data analysis environments, column names play a vital role in data sharing. They provide a common language and understanding among team members, ensuring that everyone is on the same page and working with data consistently.
In summary, Pandas Dataframe column names are not mere labels; they are essential elements that provide context, meaning, and direction to the data. By carefully crafting informative and descriptive column names, users can unlock the full potential of their data analysis and communication efforts.
Readability: Well-defined column names enhance the readability and usability of DataFrames, making it easier to work with and interpret data.
In the realm of data analysis, readability is paramount. Well-defined Pandas Dataframe column names play a transformative role in enhancing the readability and usability of DataFrames, streamlining the process of working with and interpreting data.
- Clarity and Precision
Informative column names provide clarity and precision, enabling users to quickly grasp the meaning and content of each column. This eliminates the need for guesswork or assumptions, fostering a clear understanding of the data.
- Ease of Navigation
Descriptive column names act as signposts, guiding users through the DataFrame. They allow for effortless navigation and identification of relevant data points, accelerating the exploration and analysis process.
- Error Reduction
Well-defined column names minimize the risk of errors by reducing ambiguity and confusion. Clear and concise names ensure that users are working with the correct data, leading to more accurate and reliable analysis.
- Collaboration and Communication
Standardized and meaningful column names facilitate collaboration and communication among team members. They provide a common language, ensuring that everyone is on the same page and working with data consistently, fostering effective teamwork.
In summary, well-defined Pandas Dataframe column names are not just cosmetic enhancements; they are crucial for enhancing readability, usability, and overall effectiveness in data analysis. By investing time and effort in crafting informative and descriptive column names, users can unlock the full potential of their data and make informed decisions with confidence.
Standardization: Consistent and standardized column names facilitate data integration and sharing across different systems and teams.
Within the realm of data analysis, standardization is a cornerstone for seamless data integration and sharing across diverse systems and teams. Consistent and standardized Pandas Dataframe column names play a pivotal role in achieving this objective.
Standardized column names serve as a common language, bridging the gap between different data sources and ensuring that data is interpreted and processed uniformly. This eliminates confusion and ambiguity, enabling smooth data integration and aggregation from disparate sources. Moreover, it facilitates collaboration among team members, as everyone is working with data that adheres to the same naming conventions and definitions.
Real-life examples abound where standardized column names have revolutionized data sharing and integration. Consider a multinational corporation with offices spread across the globe. Each office may have its own unique data collection and storage system, resulting in a plethora of data formats and column names. By implementing standardized column names across all systems, the corporation can effortlessly consolidate data from different offices, enabling comprehensive analysis and reporting on a global scale.
The practical significance of standardized column names extends beyond data integration. It also enhances data quality and reliability. When data is consistently named and defined, it minimizes the risk of errors and inconsistencies, leading to more accurate and trustworthy analysis and decision-making.
In summary, standardized Pandas Dataframe column names are not merely a matter of aesthetics; they are essential for effective data integration, sharing, and quality management. By adhering to consistent naming conventions, organizations can unlock the full potential of their data and make informed decisions based on a unified and reliable data foundation.
Metadata: Column names can be used as metadata to store additional information about the data, such as units of measurement or data source.
In the context of Pandas Dataframe column names, metadata plays a crucial role in enriching the data with additional information, providing context, and facilitating data analysis and interpretation.
- Data Lineage and Provenance
Column names can store information about the origin and history of the data, including its source, collection method, and any transformations or manipulations it has undergone. This metadata is invaluable for understanding the context and reliability of the data.
- Data Units and Formats
Column names can specify the units of measurement or data formats associated with each column. This information is essential for ensuring that data is interpreted correctly and consistently, especially when working with data from diverse sources.
- Data Definitions and Descriptions
Column names can provide detailed definitions and descriptions of the data contained in each column. This metadata helps users understand the meaning and significance of the data, reducing the risk of misinterpretation.
- Data Quality and Validation
Column names can store information about data quality and validation checks performed on the data. This metadata helps users assess the reliability and accuracy of the data, guiding them in making informed decisions.
By leveraging column names as metadata, Pandas DataFrames become more than just tabular data structures; they transform into rich repositories of information that empower users to work with data more effectively and confidently.
Frequently Asked Questions
This section addresses common questions and misconceptions surrounding Pandas Dataframe column names, providing clear and informative answers for better understanding and utilization.
Question 1: What is the significance of column names in Pandas DataFrames?
Answer: Column names serve as essential identifiers for each column, enabling easy data access, manipulation, and interpretation. They provide context and meaning to the data, enhancing readability and overall usability of DataFrames.
Question 2: How do column names facilitate data analysis?
Answer: Column names play a crucial role in data analysis by enabling effective filtering, grouping, and aggregation operations. They provide a basis for data exploration, allowing users to quickly identify and analyze specific aspects of the data.
Question 3: What are the best practices for choosing column names?
Answer: Column names should be informative, concise, and consistent. They should accurately reflect the content and meaning of the data, using clear and standardized language. Avoid using abbreviations or technical jargon that may not be universally understood.
Question 4: How can I modify column names in a DataFrame?
Answer: Pandas provides various methods for modifying column names, including the `rename()` and `add()` methods. These methods allow users to change existing column names or add new columns with custom names.
Question 5: What is the importance of metadata in column names?
Answer: Column names can be used as metadata to store additional information about the data, such as units of measurement, data source, or data quality information. This metadata enhances the interpretability and usability of the data.
Question 6: How do column names contribute to data sharing and collaboration?
Answer: Standardized and informative column names facilitate data sharing and collaboration by providing a common understanding of the data structure and content. They minimize confusion and errors, enabling seamless data integration and analysis across teams and organizations.
Effective utilization of Pandas Dataframe column names is crucial for efficient data management, analysis, and communication. By understanding the significance, best practices, and applications of column names, users can unlock the full potential of their data and gain valuable insights.
Transition to the next article section: Exploring Data Manipulation Techniques with Pandas DataFrames
Conclusion
In this article, we have delved into the multifaceted world of Pandas Dataframe column names, exploring their significance, best practices, and applications. Column names play a pivotal role in data identification, interpretation, readability, standardization, and metadata management.
Effective utilization of column names is essential for efficient data analysis, manipulation, and communication. By adhering to best practices and leveraging the full potential of column names, users can unlock the power of their data and gain valuable insights. Pandas Dataframe column names are not mere labels; they are the cornerstone of meaningful data exploration and informed decision-making.
Quick Fix: Miele Steam Oven Descaling Stuck
Comprehensive Guide To Stent ICD-10 Codes: Essential Information For Accurate Coding
Revolutionary Fallout: New Vegas Presidential Power Struggle




{kind=link}